NeurOS Basics
NeurOS models brain activity at the level of function and information flow among reusable modules representing neuron/assembly/group/cluster/layer/region functions. This is a level above neuron models. No explicit neuron models are required. However processing within a NeurOS module is free to use simulated neurons or any other technology to achieve its function.
Cognitive capabilities emerge from interconnecting NeurOS modules into directed neural graphs or circuits. NeurOS applications tend to resemble functional block/flow diagrams of brain connectivity.
A NeurOS module effectively transforms a high dimensional signal from an input link into changes of internal module state and a high dimensional signal on an output link:
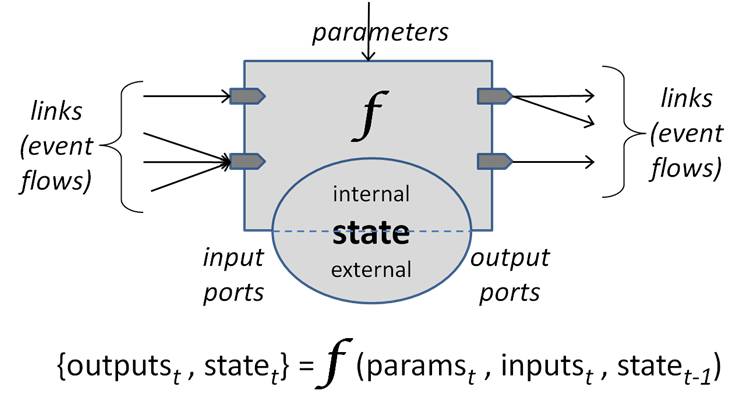
The signal representation on a link is a sparse time-series coding of changes to individual dimensional values, as a virtual-time ordered stream of events. Each event is a tuple (time, ID, value) which signifies a new value for dimension/signal ID starting at time. A module’s run() function is invoked once at each moment of virtual time where there is any change to any input signal. NeurOS ensures that events arrive in virtual time order and that all events for a virtual time moment arrive together. Modules may be stateless, have internal state, and share NeurOS-managed external state with other modules.
A biological interpretation of a NeurOS signal for a single dimension is as a function of a neuron output spike train:
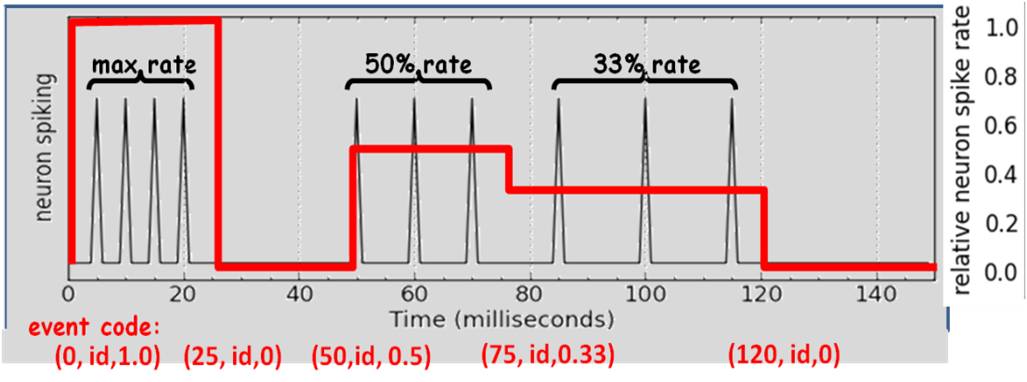
NeurOS events encode instantaneous changes to a neuron’s output spike rate, with the value normalized to the range (0,1) signifying a percentage of the maximum possible spike rate.
This signal encoding supports all three of the popular neural information encoding models: spike rate, time-to-first-spike and population coding. It is also particularly efficient for software, since computation is invoked only at moments of input signal change. From a digital hardware analogy, this signal encoding supports both edge-triggered and value-sensitive logic.
More generally, the value of an event can be a numeric scalar, vector or matrix, with sparse or dense encodings, and numeric or symbolic indices. For example, a moving image can be represented as a sequence of matrix-valued events, each event capturing a matrix of new pixel values as of the event time.
Another virtue of this signal representation is the ability to commingle multiple domain signals on a single link or from multiple links connected to one module port. For example, features derived from sight, sound and imagination can be commingled to enable cross-domain processing and memory pattern formation/recognition.
A neural graph is a directed graph of links, each link connecting an output port of one module to an input port of another (or the same) module.
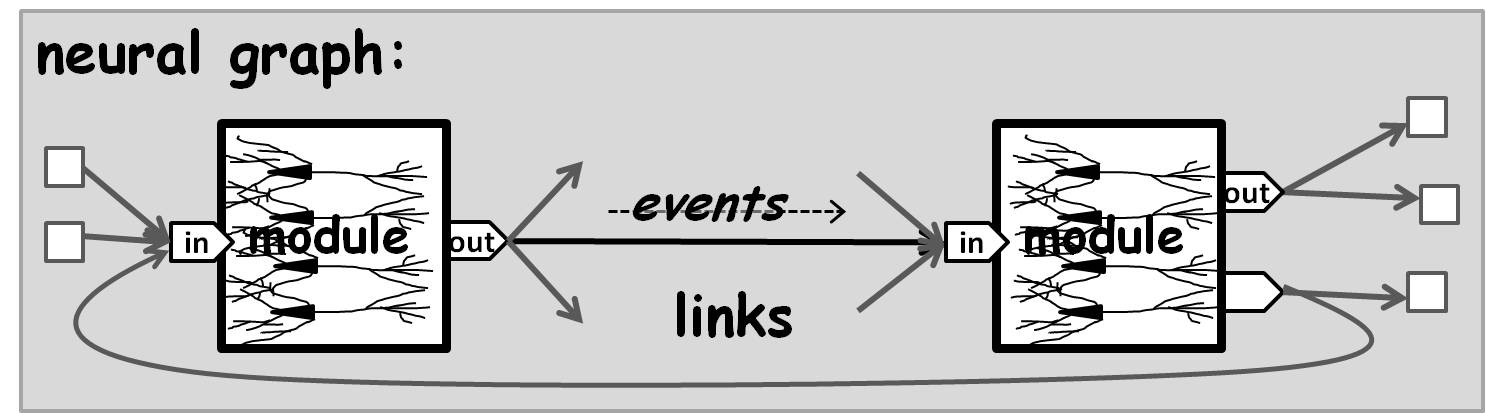
Loops are allowed, and serve an important feedback purpose in many cognitive assemblies, especially prediction, imagination, inference and behavior chaining. The outputs from a module output port can be broadcast on multiple output links. Inputs arriving at a module input port from multiple links are commingled and sorted in virtual time. Ports may be left unconnected.
Individual modules have parameters which govern their operation. Usually these are static values, but most can be set to expressions which are reevaluated at each use to model dynamic changes such as attentional control and learning rates. A graph too can have graph-global parameters, which can be referenced in module parameter expressions.
A neural graph can itself be encapsulated as a reusable module. This provides a convenient way to share and reuse particularly useful functional compositions. These also serve to structure neural application designs hierarchically with levels of detail.
This neural graph formulation and signal representation enables arbitrary processing networks of concrete through abstract concepts.
Neural graphs can be saved in an external XML file format to enable easy interconnections among multiple tools and NeurOS run-time systems. This format can optionally include saved state of a running graph, so learned experience and operational state can be captured and reused later. Learned memory patterns can be separately saved and shared with other NeurOS applications, so patterns can be learned in one application and used in others.
NeurOS modules operate as cogs in a much larger wheel, and therefore must obey some rules to ensure system stability, portability, scalability and distributability. A module can use arbitrary technologies, including multi-threading, multi-processing, files, databases, devices, remote processing, etc. However, two module instances in the same neural graph may find themselves running on completely different nodes in a shared-nothing distributed system. A module’s crucial run() function cannot block waiting for external resources, cannot run for extended time periods, and may not share resources including memory with instances of any other module type including itself. For example, module instances cannot share memory, open file handles, pipes, sockets or streams.
Aside from neural graph links, the only things that module instances may share are NeurOS-managed sharable resources: parameters and memory pattern spaces. NeurOS ensures propagation of changes to these facilities and write integrity, but provides no synchronization or serialization guarantees. This is as in biological brains: changes to broad parameters like emotional or mental state or attention, and the availability of newly learned patterns to other processing paths are inherently unsynchronized.
A module’s run() function is invoked when there are changes in its input signals. To support polling a module can set a self-timer.
A module’s parameters generally include:
- virtual time delay – how long in virtual time the module’s computation “takes”; this must always be non-zero to enable feedback loops without infinite recursion
- naming patterns for new output signal IDs
- duration of output signal bursts (if not already inherent in the module’s function)
- a gain factor to be applied to output signal values
These facilities allow NeurOS applications and assemblies to model a wide range of cognitive capabilities, easily incorporate external technologies, and build working practical cognitive applications.